表结构
1 | CREATE TABLE `scheduler_task_tracker` ( |
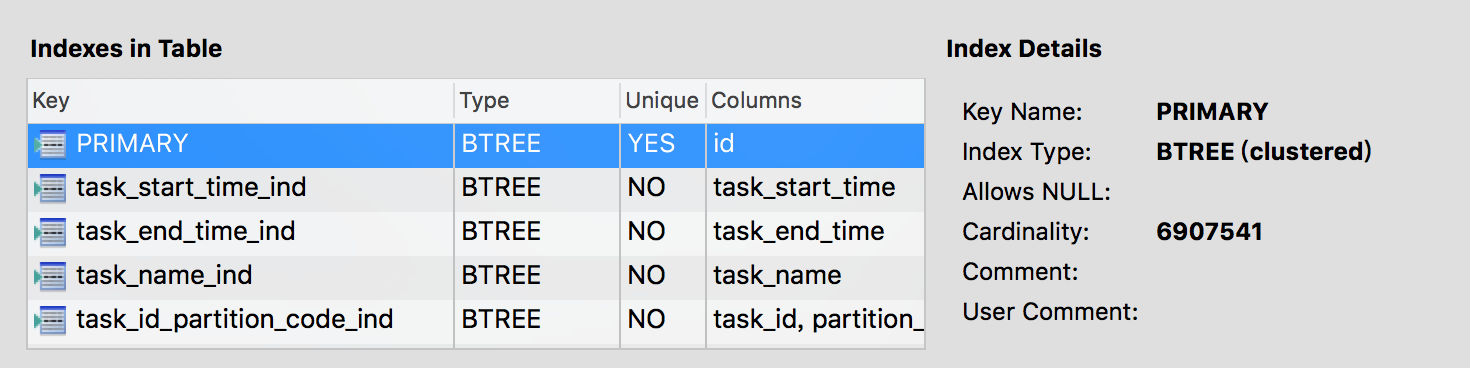
索引信息

task_start_time的Cardinality: 3453770
task_end_time的Cardinality: 6907541
查询SQL
1 | explain |
查询按照 task_start_time 排序,走索引’task_start_time_ind’ 扫描:78462行,较快

查询按照 task_end_time 排序,走索引’task_end_time_ind’ 扫描:3454055行 ,比较慢

分析如下:
- task_name 有索引但用了 like 不走这个索引
- 因为有了排序 1,2 查询都按照排序字段上的索引来查询
- task_end_time基数太大所以扫描的行数多,查询慢
怎么使得第二个查询变快呢?
- 可以建立task_start_time和task_end_time的联合查询
mysql主要根据优化器来判断使用那个索引还是使用全表扫描
- 优化器优化判断的指标
需要扫描的行数,是否使用临时表,是否排序等因素来计数查询的成本 - 扫描行数判断
那么优化器是怎么获取扫描的总行数的,其实就和抽样检查类似,因为索引是有序的,就可以使用采样统计这种算法算出大概的扫描行数,可以通过show index查看索引的Cardinality预估值。