什么是数据仓库
数据仓库 ,由数据仓库之父比尔·恩门(Bill Inmon)于1990年提出,他在1991年出版的“Building the Data Warehouse”(《建立数据仓库》)一书中所提出的数据仓库的定义——数据仓库(Data Warehouse)是一个面向主题的(Subject Oriented)、集成的(Integrated)、相对稳定的(Non-Volatile)、反映历史变化(Time Variant)的数据集合,用于支持管理决策(Decision Making Support)。
现在我们构建的数据仓库,仍然是在Bill Inmon提出的数仓理论基础之上,只不过现在根据时代不同,需求变了,衍生出各种工具和技术来支持数据仓库的发展。比如:大数据技术,数据湖技术,流计算技术等。
什么是现代数仓
现代数仓是大数据技术以及人工智能技术的发展基础上而出现的数仓架构技术。其实就是随着企业信息化、互联网技术的发展,数据量变的越来越大,数据格式越来越多,决策要求越来越苛刻,而出现的针对行解决方案。
现代数仓的技术架构
我们先来说说传统的数仓技术。其实数据仓库很早之前就有了,也就是说在现代数仓之前,有很多传统的数仓技术,例如基于teradata,ibm db2的数据仓库,只不过是数据仓库技术在大数据背景下发生了很多改变,也就是我们开始抛弃了传统构建数仓的技术,转而选择了更能满足当前时代需求的大数据技术而已,当然大数据技术并没有完整的、彻底的取代传统的技术实现,我们依然可以在很多地方看见它们的身影
所以,以大数据技术为代表的数仓建设,构成了现代数仓的基础技术架构。如下图所示:
图中展示了现代数仓基本技术架构方案。
数仓建设的方法
数仓建设的核心就是数仓的分层模型的建设。数仓的分层模型建设,主要可分为如下几个方面的建设:
- 主题域划分规范
- 分层划分规范
- 命名规范
主题域的规范
数据域划分过程
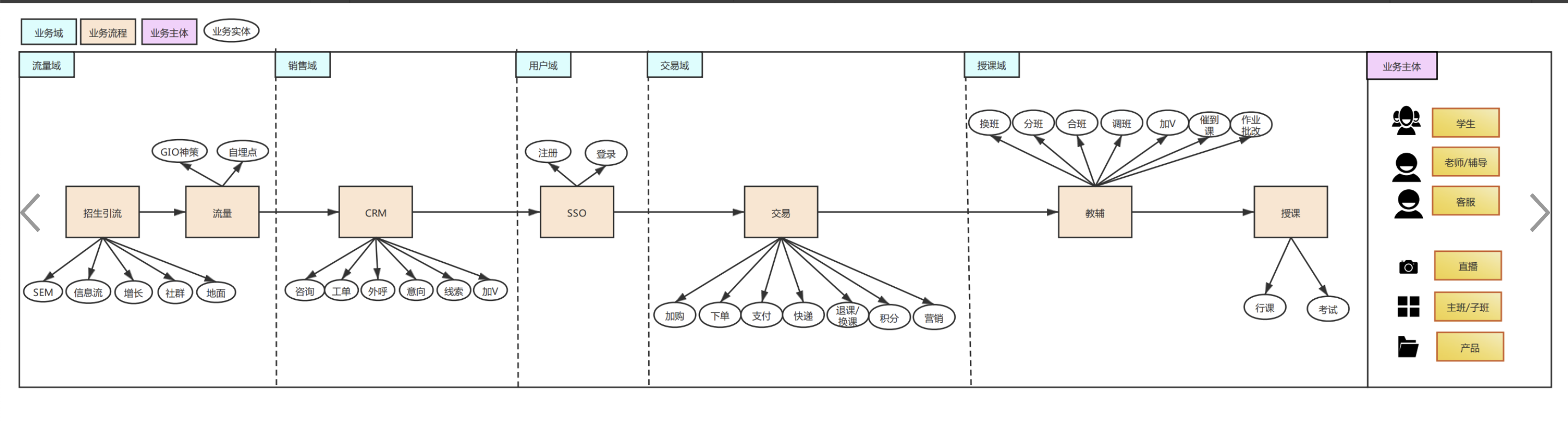
主要是按照业务过程进行主题域划分,一般分为一级主题和二级主题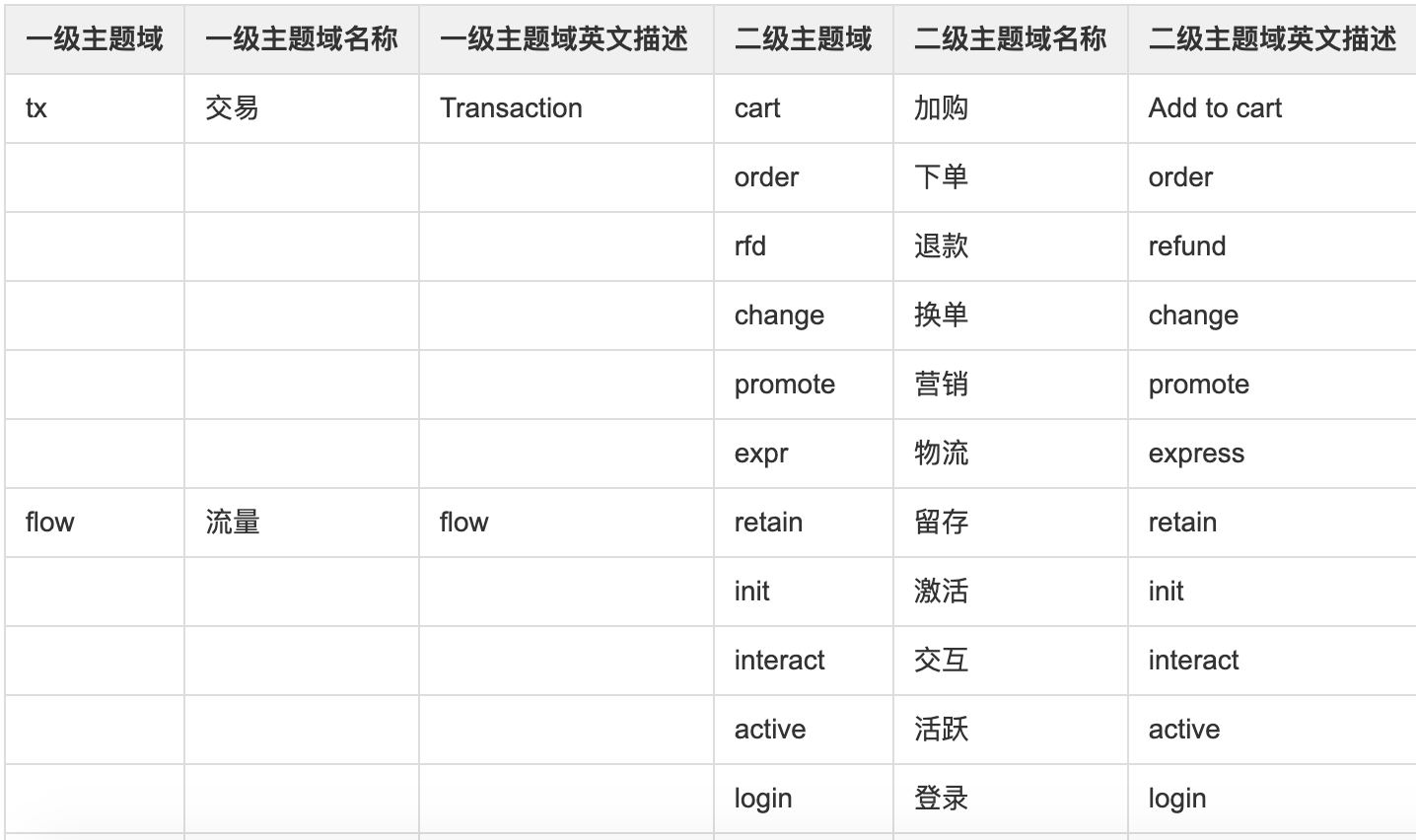
比如:交易域,我们总共分为了6个二级主题,分别为:加购、下单、退款、换单、营销、物流
命名规范
命名规范的确定对于数仓建设来说,是非常重要的。良好的命名规范不仅可以提高数仓的开发效率,减少沟通成本,而且对于数据治理,减少数据出错,提高数据质量非常有帮助。所以,在我长期实践中来说,建设一个数仓从命名规范开始很有必要。
| 层级域 | 命名规范 | 备注 |
|---|---|---|
| ods层 | ods.ods_库表_表名_更新周期(day/hour/week/month)_(da或者di) | ods_db_trade_order_tb_order_di |
| mid层 | 库名.mid_库表_表名_更新周期_(da或者di) | 此层可选,不是必须有,但是涉及到多业务系统融合的时候需要此层。如:mid_db_order_tb_order |
| mds层 | 库名.mds_一级主题简称[_二级主题简称]_自定义表名_更新周期_(da或者di) | mds_sales_order_product_detail |
| eds层 | 库名.eds_(topic/aggr)_一级主题简称[_二级主题简称]_自定义表名_更新周期_(da或者di) | |
| ads层 | 库名.ads_一级主题简称[_二级主题简称]_自定义表名_更新周期_(da或者di) | |
| 每层按照规定的前缀命名开始:ods,mid,mds,eds,ads,中间加上一二级主题 | ||
| 命名,最后确定数据周期以及数据是增量还是全量。 |
- day: 数据按天更新
- hour: 数据按小时更新
- week: 数据按周更新
- month: 数据按月更新
- year: 数据按年更新
- da: 全量数据
- di: 增量数据
分层规范
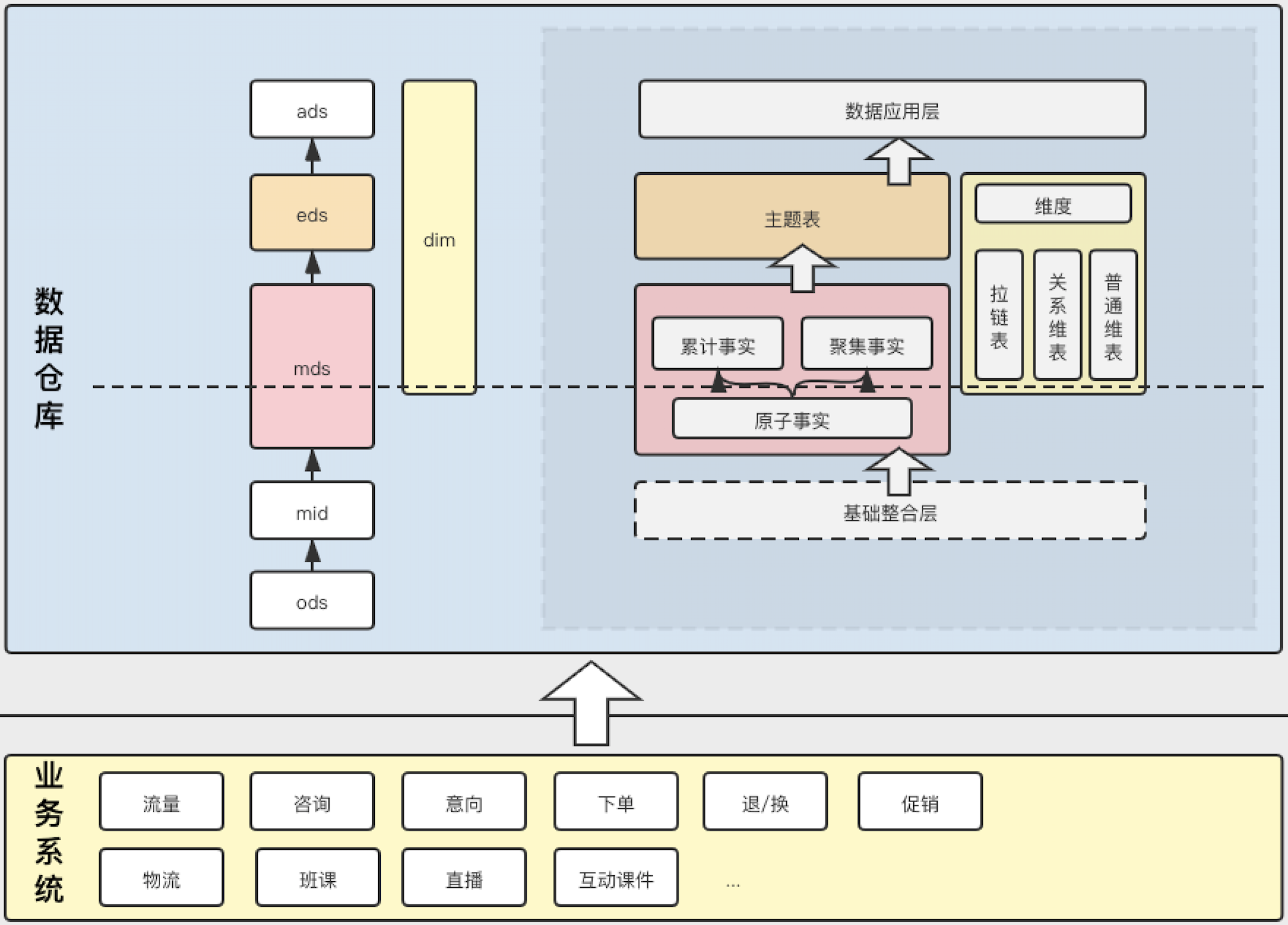
如上图所示:灰色框是提出的分层模式,mds层分为原子层与轻度汇总层,对使用者开放权限优先级eds->mds汇总层
详细说明如下:
ETL任务设计和开发
主要包括2种任务的开发
- 离线hive任务开发
- 实时flink 任务开发
离线hive任务开发
对于T+1的数据来说,我们主要使用hive sql 进行etl任务开发。ods层数据我们主要通过统一数据同步工具进行数据接入(通过包装sqoop工具进行,增量或者全量数据接入)。对于数据量超过千万的数据,进行增量接入。
mds层使用hive sql 进行etl操作后最终写入到hive数仓中,如下所示:
1 | set hive.auto.convert.join=false; |
mds层往往代码是非常复杂的,关联表多,字段多,业务复杂,所以这层是建设的重点。
对于其它层来说,开发过程类似,主要是熟悉业务过程,理解业务,开发代码。
任务开发完成后,需要进行上线操作,主要确定任务依赖的上游任务,任务运行周期,报警配置等操作,这些完成后,通过审批后,任务都上线完成。
实时flink/doris任务开发
对于T+1的任务来说,数据时效性可能不满足需求,这时我们会开发实时flink和doris任务来满足这类需求。
对于,秒级数据延迟需求的任务,我们会直接开发flink任务。整个数据处理链路如下:
- 数据源: 通过canal接入业务binlog数据到kafka中
- 数据加工: 通过flink sql来实现数据业务逻辑,最后输出到doris中
- 数据服务:通过数据API或者报表方式提供数据服务
如下是一个flink sql 例子:通过消费kafka里的线索数据,通过flink sql结合python udf(算法模型),计算出线索分 ,最后输出到rocketmq 供业务方消费使用
1 | ---------------------------------------------------- |
对于,分钟级数据需求来说,我们主要使用doris数据库,通过微批方式进行数据处理。数据处理流程如下所示: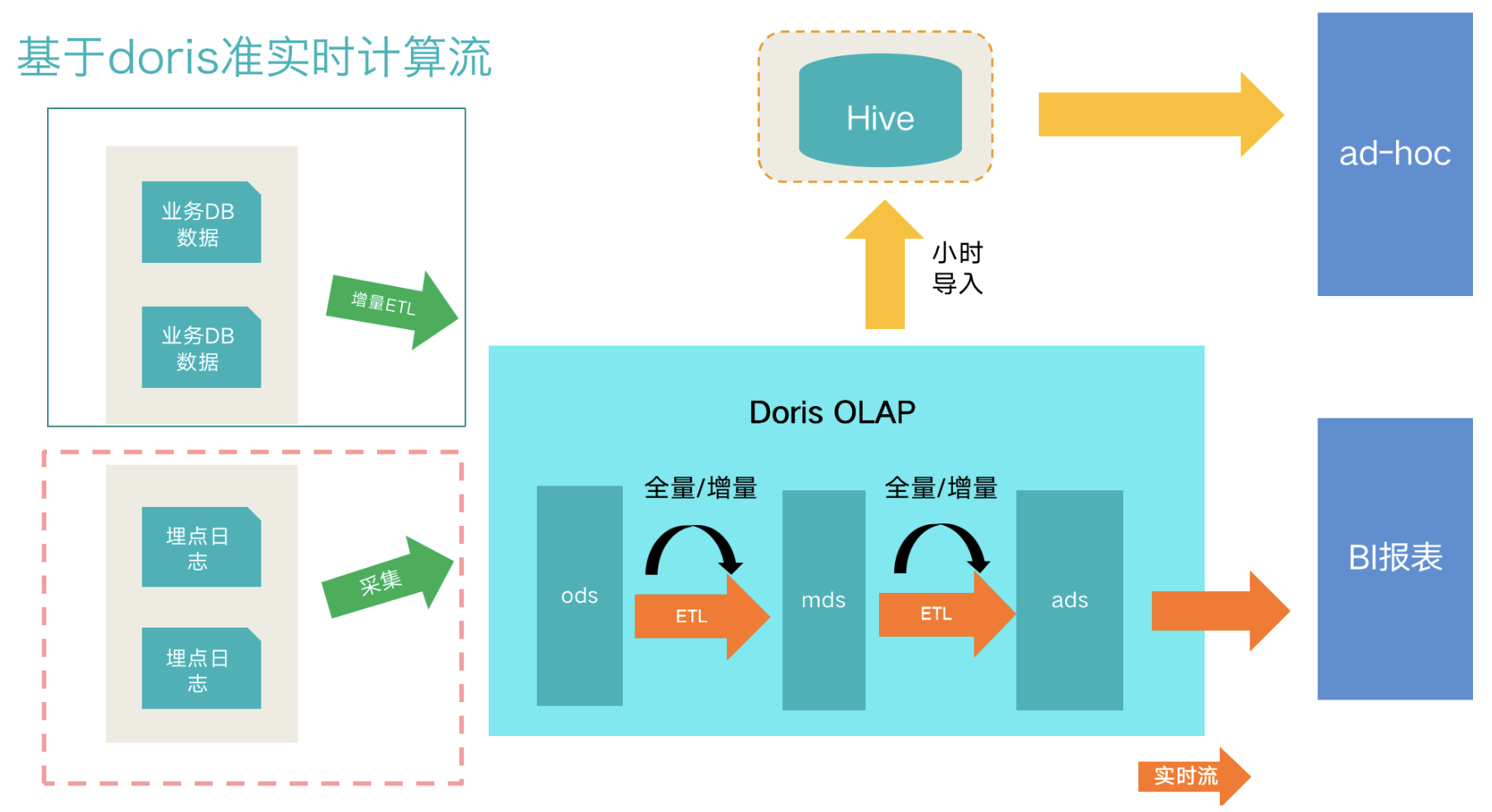
上图是目前我们采用的架构方案,总体流程如下:
- 数据接入部分,分为业务数据和日志数据。业务数据通过binlog方式收集到kafka后,在通过flink写入到doris ods层中
- mds层,采用每10分钟、半小时、一小时进行增量或全量的方式更新,构建业务模型层
- ads层,构建大宽表层加速上层查询速度
- 对于一些分析类查询需求,通过doris的export功能导出到hive通过presto提供查询
- BI查询直接通过mysql协议访问db,配合查询层缓存来提供报表分析服务
- 每层ETL任务通过自研调度系统调度运行,报警监控一体化