实时平台对比
美团实时平台
规模
- 机器几千台
- 任务万级
- 数据量 1.5亿/s
架构
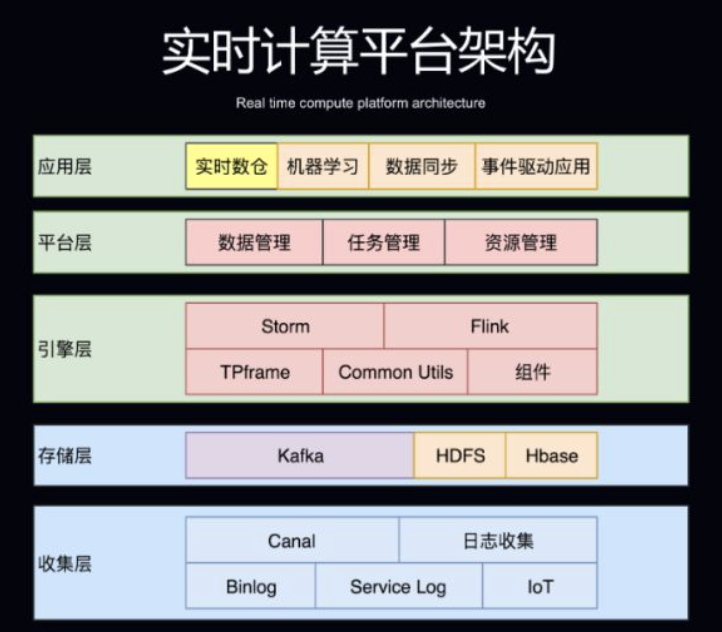
- 最底层是收集层,这一层负责收集用户的实时数据,包括 Binlog、后端服务日志以及 IoT 数据,经过日志收集团队和 DB 收集团队的处理,数据将会被收集到 Kafka 中。这些数据不只是参与实时计算,也会参与离线计算。
- 收集层之上是存储层,这一层除了使用 Kafka 做消息通道之外,还会基于 HDFS 做状态数据存储以及基于 HBase 做维度数据的存储。
- 存储层之上是引擎层,包括 Storm 和 Flink。实时计算平台会在引擎层为用户提供一些框架的封装以及公共包和组件的支持。
- 在引擎层之上就是平台层了,平台层从数据、任务和资源三个视角去管理。
- 架构的最上层是应用层,包括了实时数仓、机器学习、数据同步以及事件驱动应用等。
业务场景
- 流量数仓
- 业务数仓
- 特征数仓
实时数仓建设方式
准实时数仓
实时数仓
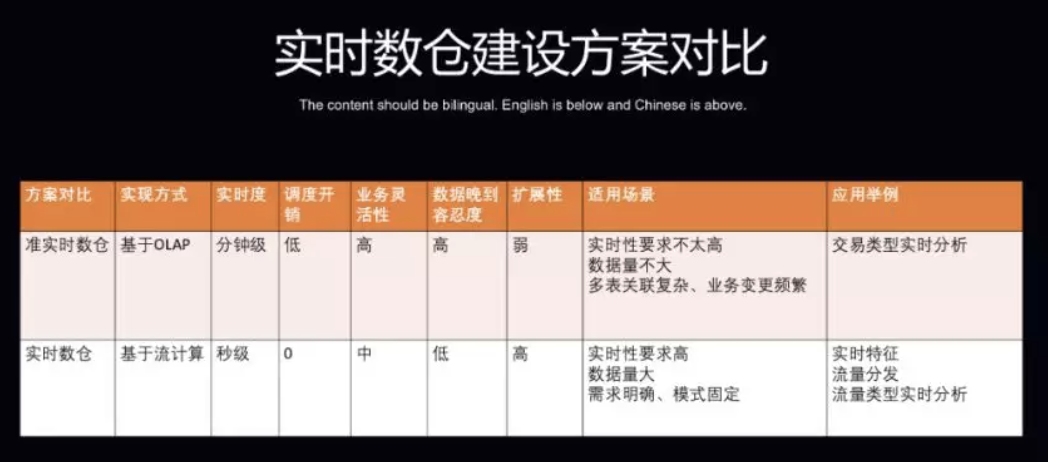
实时数仓的两种建设方式,即准实时数仓和实时数仓两种方式进行了对比。它们的实现方式分别是基于 OLAP 引擎和流计算引擎,实时度则分别是分钟和秒级。
在调度开销方面,准实时数仓是批处理过程,因此仍然需要调度系统支持,虽然调度开销比离线数仓少一些,但是依然存在,而实时数仓却没有调度开销。
在业务灵活性方面,因为准实时数仓基于 OLAP 引擎实现,灵活性优于基于流计算的方式。
在对数据晚到的容忍度方面,因为准实时数仓可以基于一个周期内的数据进行全量计算,因此对于数据晚到的容忍度也是比较高的,而实时数仓使用的是增量计算,对于数据晚到的容忍度更低一些。
在扩展性方面,因为准实时数仓的计算和存储是一体的,因此相比于实时数仓,扩展性更弱一些。
在适用场景方面,准实时数仓主要用于有实时性要求但不太高、数据量不大以及多表关联复杂和业务变更频繁的场景,如交易类型的实时分析,实时数仓则更适用于实时性要求高、数据量大的场景,如实时特征、流量分发以及流量类型实时分析。
总结:
- 根据业务场景不同选择不同的架构方式,没有一种架构是包治百病的
一站式解决方案-实时开发平台
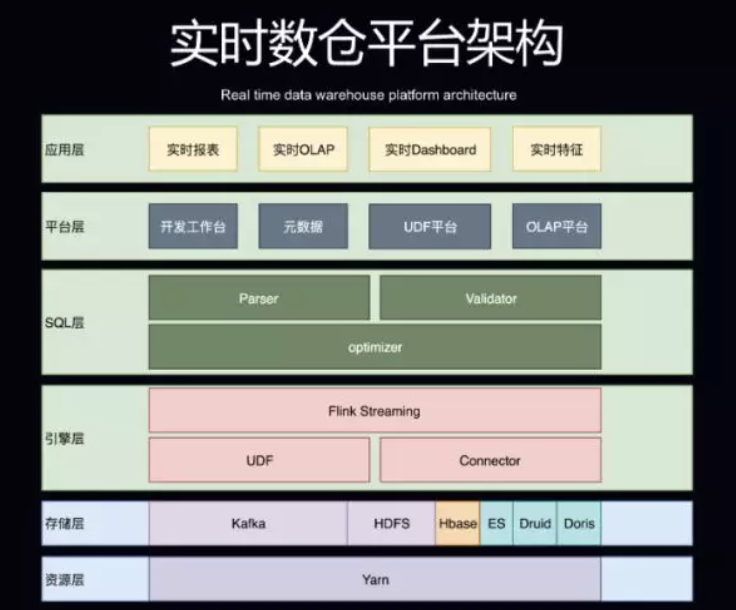
- 引擎层
flink connector 扩展和集成
- SQL层:
统一sql解析,校验
- 平台层
sql ide 支持,udf管理,olap平台 ,元数据
好未来实时开发平台
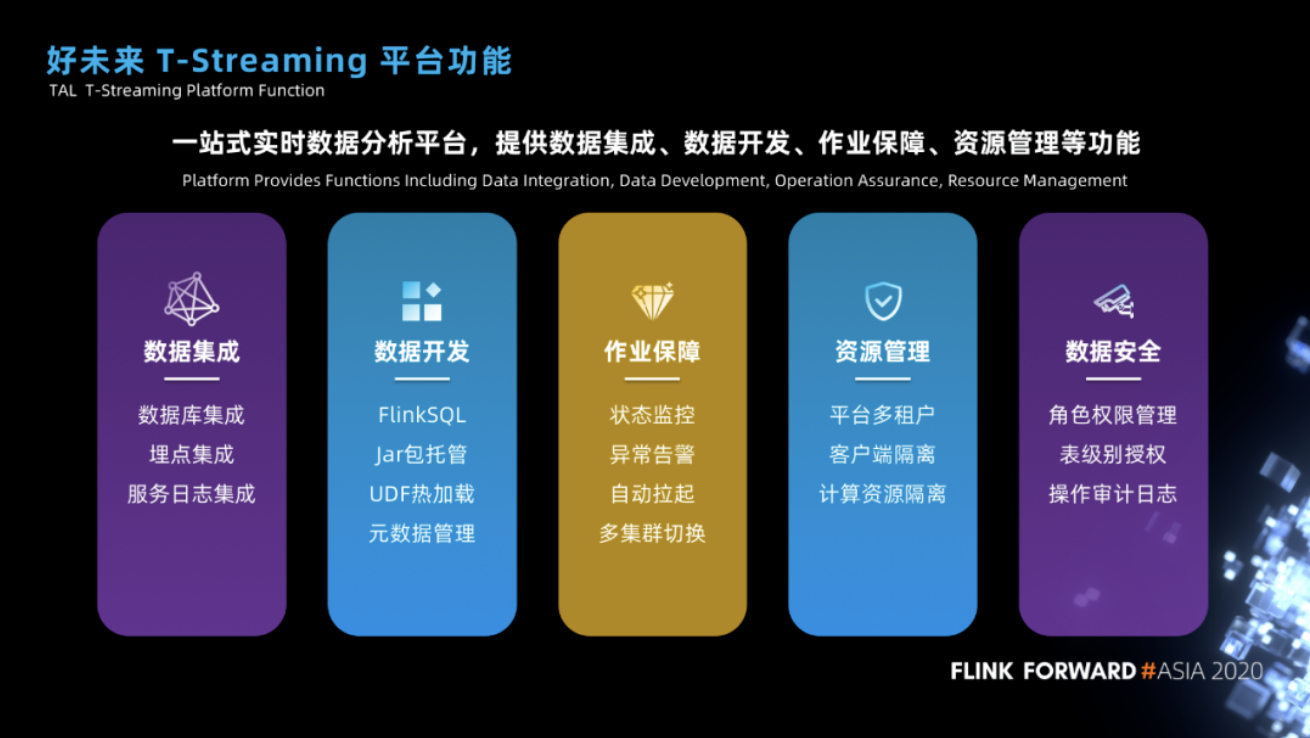
- 数据集成 方面,我们支持数据库、埋点数据、服务端日志数据的集成,为了能够提高数据集成的效率,我们提供了很多的通用模板作业,用户只需要配置即可快速实现数据的集成。
- 数据开发 方面,我们支持两种方式的作业开发,一种是 Flink SQL 作业开发、一种是 Flink Jar 包托管,在 Flink SQL 开发上我们内置了很多 UDF 函数,比如可以通过 UDF 函数实现维表 join,也支持用户自定义 UDF,并且实现了 UDF 的热加载。除此之外,我们也会记录用户在作业开发过程中的元数据信息,方便血缘系统的建设。
- 作业保障 方面,我们支持作业状态监控、异常告警、作业失败之后的自动拉起,作业自动拉起我们会自动选择可用的 checkpoint 版本进行拉起,同时也支持作业在多集群之间的切换。
- 资源管理 方面,我们支持平台多租户,每个租户使用 namespace 进行隔离、实现了不同事业部、不同用户、不同版本的 Flink 客户端隔离、实现了计算资源的隔离。
- 数据安全 方面,我们支持角色权限管理、表级别权限管理、操作审计日志查询等功能。
对比