在网上看到这篇文章,觉得写的挺好的,可以帮助大家理解fink中的Exactly Once和At Least Once语义到底是什么。
看完本文,你能get到以下知识
- 介绍CheckPoint如何保障Flink任务的高可用
- CheckPoint中的状态简介
- 如何实现全域一致的分布式快照?
- 什么是barrier?什么是barrier对齐?
- 证明了:为什么barrier对齐就是Exactly Once?为什么barrier不对齐就是 At Least Once?
有状态函数和运算符在各个元素/事件的处理中存储数据(状态数据可以修改和查询,可以自己维护,根据自己的业务场景,保存历史数据或者中间结果到状态中)
例如:
当应用程序搜索某些事件模式时,状态将存储到目前为止遇到的事件序列。
在每分钟/小时/天聚合事件时,状态保存待处理的聚合。
当在数据点流上训练机器学习模型时,状态保持模型参数的当前版本。
当需要管理历史数据时,状态允许有效访问过去发生的事件。
什么是状态?
- 无状态计算的例子
- 比如:我们只是进行一个字符串拼接,输入 a,输出 a_666,输入b,输出 b_666
- 输出的结果跟之前的状态没关系,符合幂等性。
- 幂等性:就是用户对于同一操作发起的一次请求或者多次请求的结果是一致的,不会因为多次点击而产生了副作用
- 有状态计算的例子
- 计算pv、uv
- 输出的结果跟之前的状态有关系,不符合幂等性,访问多次,pv会增加
Flink的CheckPoint功能简介
Flink CheckPoint 的存在就是为了解决flink任务failover掉之后,能够正常恢复任务。那CheckPoint具体做了哪些功能,为什么任务挂掉之后,通过CheckPoint能使得任务恢复呢?
CheckPoint是通过给程序快照的方式使得将历史某些时刻的状态保存下来,当任务挂掉之后,默认从最近一次保存的完整快照处进行恢复任务。问题来了,快照是什么鬼?能吃吗?
SnapShot翻译为快照,指将程序中某些信息存一份,后期可以用来恢复。对于一个Flink任务来讲,快照里面到底保存着什么信息呢?
晦涩难懂的概念怎么办?当然用案例来代替咯,用案例让大家理解快照里面到底存什么信息。选一个大家都比较清楚的指标,app的pv,flink该怎么统计呢?
我们从Kafka读取到一条条的日志,从日志中解析出app_id,然后将统计的结果放到内存中一个Map集合,app_id做为key,对应的pv做为value,每次只需要将相应app_id 的pv值+1后put到Map中即可

flink的Source task记录了当前消费到kafka test topic的所有partition的offset,为了方便理解CheckPoint的作用,这里先用一个partition进行讲解,假设名为 “test”的 topic只有一个partition0
- 例:(0,1000)
- 表示0号partition目前消费到offset为1000的数据
- 例:(0,1000)
flink的pv task记录了当前计算的各app的pv值,为了方便讲解,我这里有两个app:app1、app2
- 例:(app1,50000)(app2,10000)
- 表示app1当前pv值为50000
- 表示app2当前pv值为10000
- 每来一条数据,只需要确定相应app_id,将相应的value值+1后put到map中即可
- 例:(app1,50000)(app2,10000)
该案例中,CheckPoint到底记录了什么信息呢?
记录的其实就是第n次CheckPoint消费的offset信息和各app的pv值信息,记录一下发生CheckPoint当前的状态信息,并将该状态信息保存到相应的状态后端。(注:状态后端是保存状态的地方,决定状态如何保存,如何保障状态高可用,我们只需要知道,我们能从状态后端拿到offset信息和pv信息即可。状态后端必须是高可用的,否则我们的状态后端经常出现故障,会导致无法通过checkpoint来恢复我们的应用程序)
chk-100
- offset:(0,1000)
- pv:(app1,50000)(app2,10000)
该状态信息表示第100次CheckPoint的时候, partition 0 offset消费到了1000,pv统计结果为(app1,50000)(app2,10000)
任务挂了,如何恢复?
- 假如我们设置了三分钟进行一次CheckPoint,保存了上述所说的 chk-100 的CheckPoint状态后,过了十秒钟,offset已经消费到 (0,1100),pv统计结果变成了(app1,50080)(app2,10020),但是突然任务挂了,怎么办?
- 莫慌,其实很简单,flink只需要从最近一次成功的CheckPoint保存的offset(0,1000)处接着消费即可,当然pv值也要按照状态里的pv值(app1,50000)(app2,10000)进行累加,不能从(app1,50080)(app2,10020)处进行累加,因为 partition 0 offset消费到 1000时,pv统计结果为(app1,50000)(app2,10000)
- 当然如果你想从offset (0,1100)pv(app1,50080)(app2,10020)这个状态恢复,也是做不到的,因为那个时刻程序突然挂了,这个状态根本没有保存下来。我们能做的最高效方式就是从最近一次成功的CheckPoint处恢复,也就是我一直所说的chk-100
- 以上讲解,基本就是CheckPoint承担的工作,描述的场景比较简单
疑问,计算pv的task在一直运行,它怎么知道什么时候去做这个快照?或者说计算pv的task怎么保障它自己计算的pv值(app1,50000)(app2,10000)就是offset(0,1000)那一刻的统计结果呢?
- flink是在数据中加了一个叫做barrier的东西(barrier中文翻译:栅栏),下图中红圈处就是两个barrier
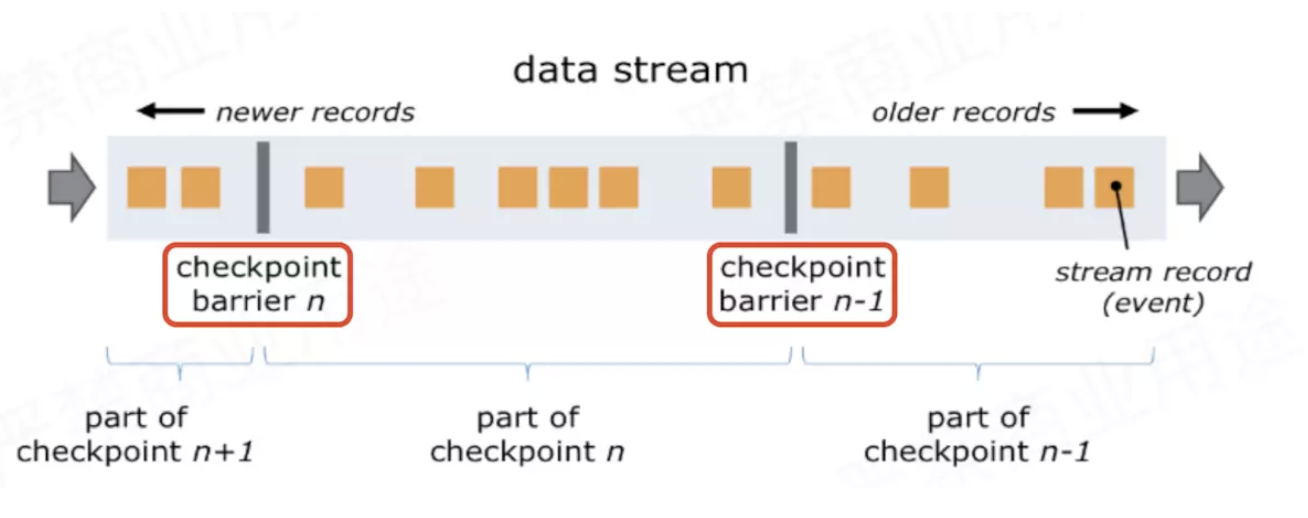
- flink是在数据中加了一个叫做barrier的东西(barrier中文翻译:栅栏),下图中红圈处就是两个barrier
barrier从Source Task处生成,一直流到Sink Task,期间所有的Task只要碰到barrier,就会触发自身进行快照
- CheckPoint barrier n-1处做的快照就是指Job从开始处理到 barrier n-1所有的状态数据
- barrier n 处做的快照就是指从Job开始到处理到 barrier n所有的状态数据
对应到pv案例中就是,Source Task接收到JobManager的编号为chk-100的CheckPoint触发请求后,发现自己恰好接收到kafka offset(0,1000)处的数据,所以会往offset(0,1000)数据之后offset(0,1001)数据之前安插一个barrier,然后自己开始做快照,也就是将offset(0,1000)保存到状态后端chk-100中。然后barrier接着往下游发送,当统计pv的task接收到barrier后,也会暂停处理数据,将自己内存中保存的pv信息(app1,50000)(app2,10000)保存到状态后端chk-100中。OK,flink大概就是通过这个原理来保存快照的
- 统计pv的task接收到barrier,就意味着barrier之前的数据都处理了,所以说,不会出现丢数据的情况
barrier的作用就是为了把数据区分开,CheckPoint过程中有一个同步做快照的环节不能处理barrier之后的数据,为什么呢?
- 如果做快照的同时,也在处理数据,那么处理的数据可能会修改快照内容,所以先暂停处理数据,把内存中快照保存好后,再处理数据
- 结合案例来讲就是,统计pv的task想对(app1,50000)(app2,10000)做快照,但是如果数据还在处理,可能快照还没保存下来,状态已经变成了(app1,50001)(app2,10001),快照就不准确了,就不能保障Exactly Once了
多并行度、多Operator情况下,CheckPoint过程
分布式状态容错面临的问题与挑战
- 如何确保状态拥有精确一次的容错保证?
- 如何在分布式场景下替多个拥有本地状态的算子产生一个全域一致的快照?
- 如何在不中断运算的前提下产生快照?
多并行度、多Operator实例的情况下,如何做全域一致的快照
- 所有的Operator运行过程中遇到barrier后,都对自身的状态进行一次快照,保存到相应状态后端
- 对应到pv案例:有的Operator计算的app1的pv,有的Operator计算的app2的pv,当他们碰到barrier时,都需要将目前统计的pv信息快照到状态后端
- 所有的Operator运行过程中遇到barrier后,都对自身的状态进行一次快照,保存到相应状态后端
作者:fanrui
链接:https://www.jianshu.com/p/8d6569361999